👕 크롤링 애플리케이션은 JBLY 프로젝트 요구 사항인 "파이썬 환경에서 최소 세 개 이상의 쇼핑몰을 모아볼 수 있다."를 수행하는 애플리케이션입니다. 시리즈 포스팅은 성능 개선 과정에서 겪은 문제점과 해결하는 과정을 담고 있습니다.
✒️ 첫 번째 요구사항 충족 글은 성능이 개선되기 전 요구 사항 달성 과정을 포스팅합니다. (160분 소요)
✒️ 두 번째 도구 선택의 중요성 글은 Selenium Tool 걷어내는 과정에서 성능 개선 방법에 대해 포스팅합니다. (30분대로 성능 개선)
✒️ 세 번째 병렬 처리 글은 병렬 처리를 통해 성능을 높일 수 있는 방법에 대해 포스팅합니다.(4분대로 성능 개선)
🍎 우선, Selenium에서 성능을 향상할 수 있는 방법을 찾아봤습니다.
🍏 Selenium을 사용해 요구사항을 충족했음에도 불구하고 Crawling Application 실행 성능이 잘 나오지 않아 Selenium Tool에서 성능을 높일 수 있는 방법을 찾아봤습니다.
- Selenium을 통해 Web Driver를 띄워 조작하는 방법에선 기본값으로 입력한 URL의 페이지를 직접 보여줍니다. Web Page를 띄우는 작업(모니터에 그리는 작업)은 리소스가 많이 소요되는 작업입니다. Selenium에선 Web Driver에 설정 값을 추가해 Display에 그리는 작업을 하지 않도록 설정할 수 있습니다.
- Headless option : 이 옵션은 Browser를 HeadLess Mode로 실행하도록 지정하는 것입니다. 즉, GUI 없이 Background에서 실행됩니다. 이 옵션을 사용하면 Browser를 화면에 표시하지 않고도 WebDriver를 사용할 수 있습니다.
- No-sandbox : 이 옵션은 Browser가 보안 취약점에 노출될 가능성을 최소화하기 위해 사용되는 Sandbox 보호 기능을 해제하는 것입니다. JBLY 프로젝트에서 Web Driver를 사용할 때, 해당 옵션을 사용해 Sandbox 기능을 OFF로 돌렸습니다. 이유는 보안이 목적이 아닌 가능한 빠르게 Application을 실행하는 것이 목표이기 때문입니다.
- Disable-dev-shm-usage : 이 옵션은 공유 메모리 파일 시스템 크기를 제한하지 않게 설정하는 것입니다. 기본적으로 큰 메모리를 사용하게 되면 파일 시스템의 크기가 부족하여 Browser가 충돌할 수 있습니다. Crawling 할 데이터의 크기가 혹시나 파일 시스템의 크기를 넘어 충돌하게 되면 Application은 종료가 됩니다. 따라서, JBLY 프로젝트에선 파일 시스템 크기 제한하지 않도록 설정했습니다.
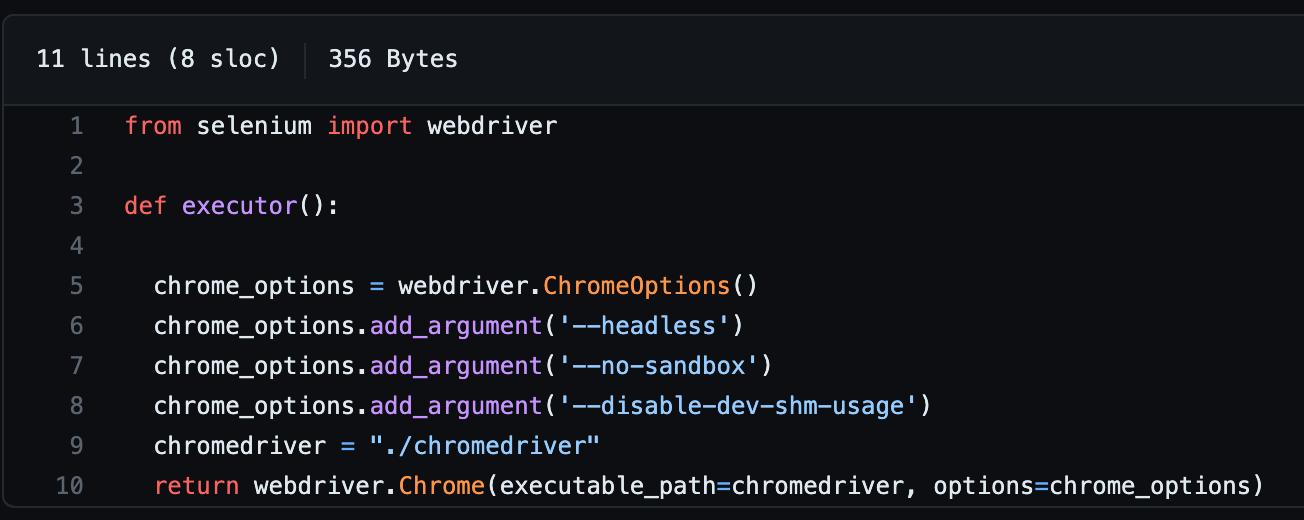
- Code Level에서 Web Driver 생성을 최소화하여 성능을 개선할 수 있었습니다. 기존 코드에선 상세 페이지를 찾는 Looping 안에 상세 페이지를 찾는 Web Driver를 두어 매 번 상세페이지를 방문할 때마다 Web Driver를 생성했습니다. 아래와 같이 코드를 작성하게 된다면 Web Driver의 생성, close()를 반복하는 것이고 이는 큰 리소스가 필요한 작업입니다. (코드를 보고 싶다면 여기에서 확인할 수 있습니다.)
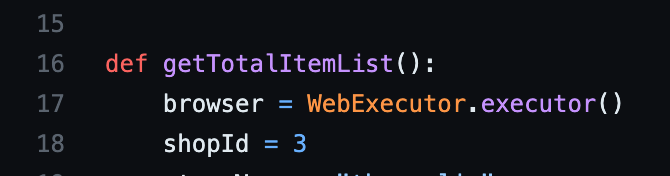
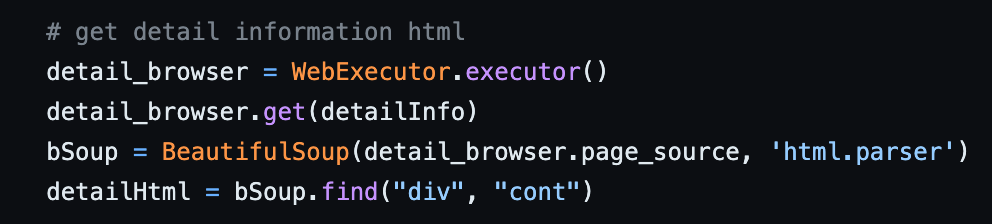
- 상세 페이지 Crawling 데이터는 Web Driver를 통해 가져오는 것이 아닌 상세 페이지 URL Request를 통해 Response를 가져오고 BeautifulSoup을 사용해 원하는 데이터를 가져오는 방식으로 해결했습니다. 결과적으로 두 번의 Web Driver 사용을 한 번으로 줄여 Application 동작 시간을 줄일 수 있었습니다.(해당 코드는 여기서 확인할 수 있습니다.)
⚠️ Selenium Tool 사용 시 성능을 높일 수 있는 옵션을 적용해 봤지만 기대한 만큼 성능 개선이 이뤄지지 않았습니다.
🍏Selenium 성능 개선 옵션을 적용해 봤지만 여전히 Application은 느렸습니다. 많은 고민을 하던 중 "사용하는 도구에 문제가 있지 않을까?"라는 의심을 갖게 되었고 Selenium의 단점을 알고 난 후 성능 저하를 일으키는 것이 Tool에 있다는 것을 발견했습니다.
🍎 Selenium의 단점
🍏 Selenium은 강력한 기능을 갖고 있는 대신 큰 비용을 치러야 한다는 점을 알지 못하고 동적 처리만 제공한다는 이유 하나만으로 사용했습니다.
- HeadLess를 적용하고 Web Driver의 숫자를 줄이더라도 실행 시간을 줄이는데 한계가 있었습니다. Selenium은 자바스크립트가 로드된 후 사용자가 사용할 수 있습니다. 이 부분에서 큰 비용이 발생하고 있었습니다.
- 프로젝트에 필요한 데이터는 Rendering된 결과가 아닌 해당 페이지의 HTML_Source입니다. 즉, Rendering이 다 될 때까지 기다릴 필요가 없다는 이야기입니다.

- Rendering이 완료될 때까지 시간은 대략 2,300ms입니다. 이때, 대략적으로 109(pages) * 2,300ms = 250,700 ms 가 소요됩니다. 다른 작업이 완료되지 않고 Crawling 대상 페이지만 소요되는 최소 시간이 4분 17초가 소요됩니다. 여기에 다른 작업까지 추가된다면 모든 작업에 추가가 되어 동기처리 되니 소요되는 시간은 급격하게 높아지게 됩니다.
🍎 Crawling을 할 때, Selenium Tool을 사용하지 않고 해결할 수 없을까?
- Selenium을 사용하지 않고 Crawling을 진행하기 위해선 Web에서 사용자에게 페이지를 띄우는 과정을 알아야 합니다.
- 요청을 보내면 요청을 받은 서버 쪽과 Connection을 맺고 Switch - Router 들을 지나 서버에게 요청합니다. 이를 통해 응답을 받게 되고 Web Engine에 응답을 나타나게 되는데 이때, HTML Source를 먼저 읽고 Source에 존재하는 CSS, JS 라인을 이후에 불러오는 형식을 갖고 있습니다.
이를 통해 알 수 있는 것은 Crawling 시 필요한 데이터는 제일 먼저 받아오는 HTML Source에서 전부 알 수 있다는 것입니다.

- 모든 파일을 다 받아올 필요는 없습니다. 필요한 파일은 오직 하나 제일 먼저 응답으로 오는 HTML File입니다. 위 이미지에서 확인할 수 있듯이, HTML File만 가져오게 된다면 274ms의 시간만 필요하며 전체 렌더링하는 시간 대비 대략 10분의 1의 시간만 필요합니다.
❓그렇다면 동적 처리로 알게 된 마지막 페이지 부분은 어떤 방식으로 처리해야 하나요?
- Selenium을 통해 Crawling을 진행했을 땐, Rendering 된 전체 데이터에서 마지막 페이지에 관련한 부분을 찾아 해결할 수 있었지만 Selenium을 걷어내고 난 후 마지막 페이지를 어떤 방식으로 찾아내야 하는지 어려움을 겪었습니다.
- 상품 URL Query를 보고 쉽게 마지막 페이지를 찾을 수 있을 거라 생각했지만 마지막 페이지 넘어서 페이지를 입력한 경우("https://example.com/category/pants/26/?page=50", 해당 페이지는 상품이 없습니다.) 예외를 발생시키는 것이 아닌 서버에서 빈 값을 내보내 페이지를 만드는 것을 볼 수 있었습니다.
- 답은 Request로 받아온 Response에서 찾을 수 있었습니다. 지금껏 BeautifulSoup을 통해 HTML Source를 얻을 수 있다고 생각했지만 아닙니다. response.text를 통해 Source 전체를 얻을 수 있었습니다.
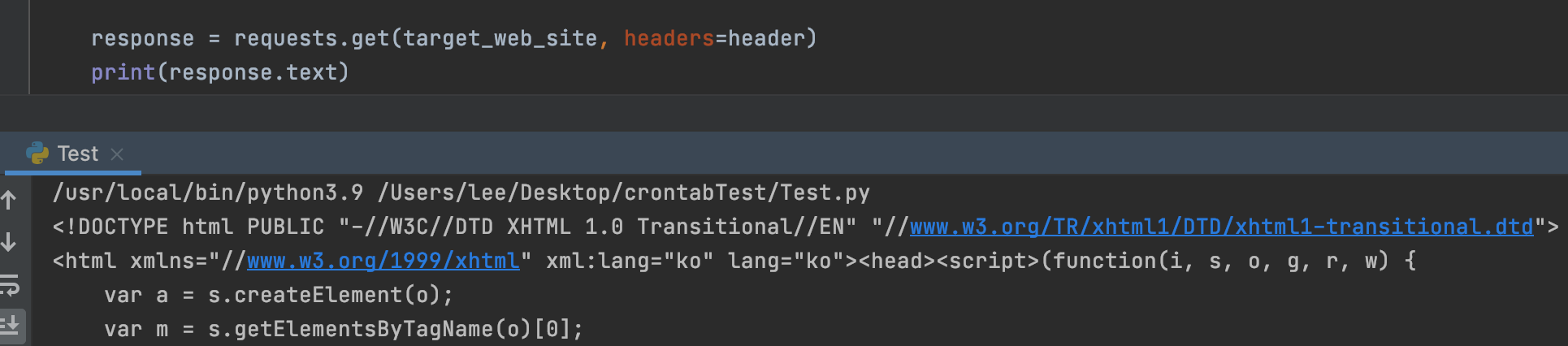
- 빈 배열을 반환한다고 했으니 상품을 다루고 있는 Tag의 유무를 확인하면 마지막 페이지를 찾을 수 있습니다.!
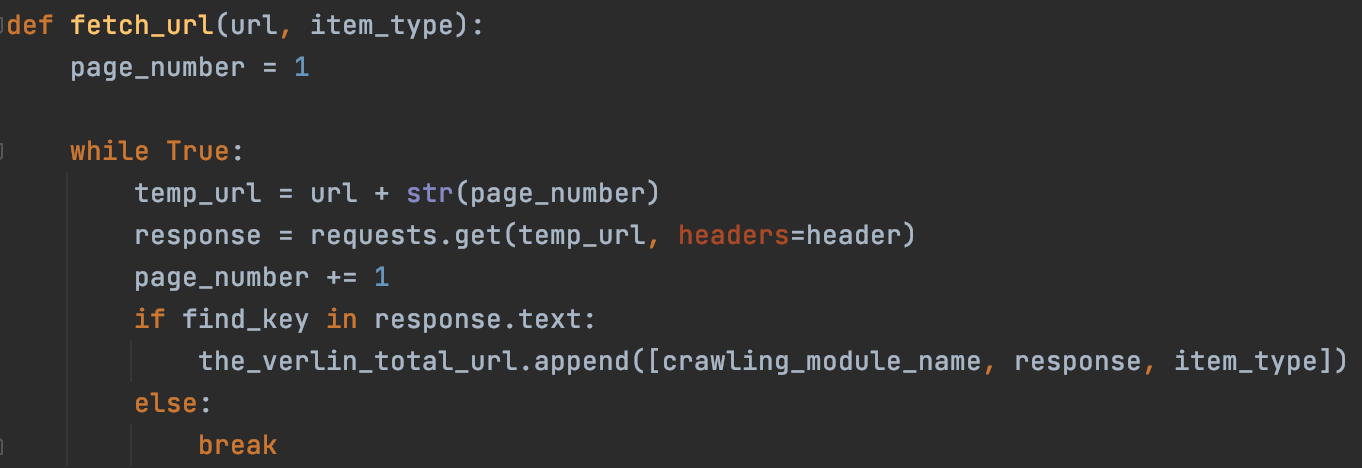
📖 [Effective Java]에서 다룬 내용 중 "Null 대신 비어있는 배열이나 Collecion을 반환하자"를 눈으로 확인한 순간입니다. 이와 같이 말하는 이유는 Null을 반환하면 API는 사용하기 어렵고 오류 처리 코드도 늘어나게 되며, 성능이 좋은 것도 아니기 때문에 빈 배열이나 빈 Collecion을 반환하는 것이 Null로 처리하는 것보다 좋기 때문입니다.
✅ Selenium을 걷어내는 작업을 통해 성능을 개선시킬 수 있었습니다.
- 아래 이미지는 Selenium을 사용해 Application을 실행했을 때 시간과 Selenium을 걷어낸 후 시간을 비교한 이미지입니다. 45분 34초에서 18분 38초로 성능 개선 모습을 볼 수 있습니다.
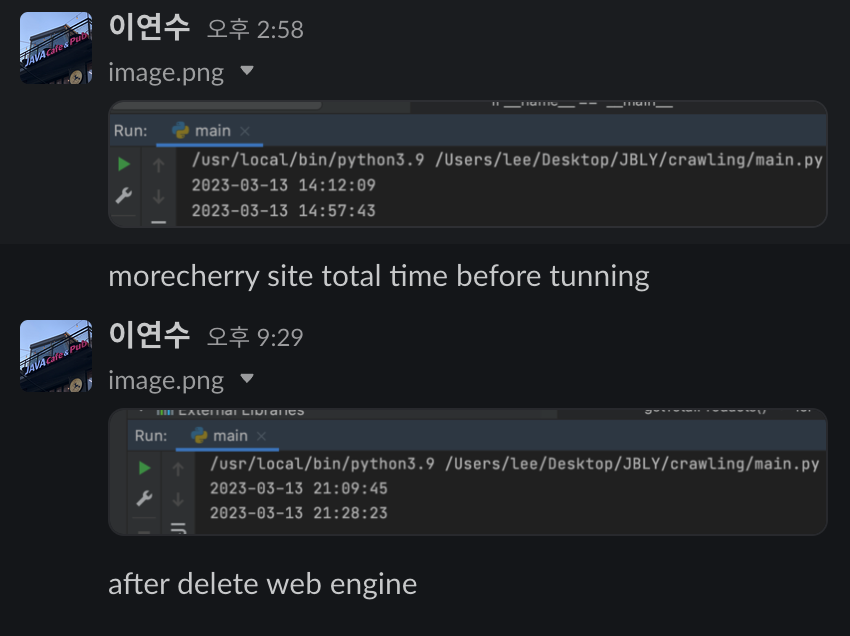
- Crawling Application 실행 시간을 160분에서 30분대로 줄일 수 있었습니다. 거의 5분의 1로 줄일 수 있었지만 1000개의 사이트 모아보기를 서비스를 목표로 한다면 성능을 더 높여야 합니다.
- 대략적인 계산으로 하루 처리할 수 있는 Crawling 사이트는 144개입니다. 성능 개선을 했더라도 모든 사이트를 Crawling 할 때, (144 * 7 = 1008) 일주일 정도 소요됩니다.
| Crawling Application | 쇼핑몰 1,000개 Crawling 시간 |
| Selenium을 걷어내기 전 | 한 달 이상 |
| Selenium을 걷어낸 후 | 일주일 |
- 위 표를 보고 알 수 있듯이 대략적으로 계산한다면 4분의 1로 비용을 절감할 수 있었습니다.
- 하지만, 상품 업데이트 주기가 일주일이라면 소비자와 쇼핑몰 데이터 사이 데이터 정합성은 어긋날 가능성이 높습니다. 이를 위해 병목 지점을 찾고 개선해야 합니다.
🔜 다음 포스팅에선 병목 지점을 찾고 Multi Process와 Multi Thread를 활용해 해결해 30분대에서 4분대로 성능 개선하는 과정을 포스팅하겠습니다. 긴 글 읽어주셔서 감사합니다.
➕ Web에 떠다니는 도구의 장점만 보고 도입하지 말고 단점 또한 생각해 프로젝트의 성격과 잘 맞는지 확인하고 사용해야 한다는 것을 알게 되었습니다. 의심하지 않는다면 해당 도구를 걷어내는데 큰 리소스가 들어갈 수 있습니다. Selenium은 절대 좋지 않은 도구가 아닙니다. 단지 JBLY 프로젝트의 성격과 맞지 않을 뿐입니다.
📚 참고 사이트
Web Browser에서 요청 시 발생하는 상황을 알 수 있습니다.
Web 동적 처리를 제공하는 Selenium의 사용법을 배울 수 있습니다.
🍎 Selenium을 걷어낸 PR은 링크를 통해 확인할 수 있습니다.
[#111] Selenium remove by EcoFriendlyAppleSu · Pull Request #112 · f-lab-edu/JBLY
기능 Selenium 툴을 걷어냅니다. 상세 내용 ❌ issue number and link 🍎 #111
github.com
'Dev' 카테고리의 다른 글
| REST API 설계 및 사용 시 참고 사항 (1) | 2024.09.01 |
|---|---|
| Crawling 성능 40배 올리기, 160분에서 4분대로 -병렬 처리- (4) | 2023.04.06 |
| Crawling 성능 40배 올리기, 160분에서 4분대로 -요구사항 충족- (2) | 2023.04.04 |
| 동기화와 병렬 처리 둘의 상관 관계 그리고 Java (0) | 2023.04.03 |
| Process와 Thread. 다다익프? 다다익쓰? (0) | 2023.04.03 |