-
Crawling 성능 40배 올리기, 160분에서 4분대로 -병렬 처리-Dev Azit/크롤링 성능튜닝 여행기 2023. 4. 6. 16:33
👕 크롤링 애플리케이션은 JBLY 프로젝트 요구 사항인 "파이썬 환경에서 최소 세 개 이상의 쇼핑몰을 모아볼 수 있다."를 수행하는 애플리케이션입니다. 시리즈 포스팅은 성능 개선 과정에서 겪은 문제점과 해결하는 과정을 담고 있습니다.
✒️ 첫 번째 요구사항 충족 글은 성능이 개선되기 전 요구 사항 달성 과정을 포스팅합니다. (160분 소요)
✒️ 두 번째 도구 선택의 중요성 글은 Selenium Tool 걷어내는 과정에서 성능 개선 방법에 대해 포스팅합니다. (30분대로 성능 개선)
✒️ 세 번째 병렬 처리 글은 병렬 처리를 통해 성능을 높일 수 있는 방법에 대해 포스팅합니다.(4분대로 성능 개선)
🍏 지금까지 Selenium을 사용해 Crawling을 진행하고 Selenium 도구의 단점을 알게 되어 걷어내는 과정에서 성능 개선을 할 수 있었습니다. 이번 포스팅에서는 병목이 일어나는 지점을 찾아보고 해당 작업을 처리하는 과정을 다루겠습니다.
❗️ 본 이야기를 하기 전 알아야 할 것이 있습니다.
❓ 병목 지점이라는 것은 무엇인가요?
• 컴퓨터 환경에서 병목 지점은 시스템의 성능을 제한하는 가장 느린 구성 요소를 나타냅니다. 즉, 시스템 내의 다른 구성 요소들이 병목 지점에서 대기를 해야 하기 때문에 전반적인 성능이 저하되는 현상을 의미합니다.
❓CPU Bound 작업은 무엇인가요?
• CPU Bound 작업이란, CPU가 작업을 수행하는 동안 다른 HW Resource 사용이 적은 작업을 의미합니다. 예를 들면, 대규모 계산, DB Query 처리, 이미지 또는 비디오 처리 등이 CPU Bound 작업에 해당됩니다. 이러한 작업은 대개 CPU를 많이 사용하여 처리량과 처리 속도가 높습니다.
❓I/O Bound 작업은 무엇인가요?
• I/O Bound 작업은 주로 입출력(Input/Output) 작업이 많은 작업을 의미합니다. 예를 들면, File read/write, Network 통신, DB 입출력 등이 I/O Bound 작업에 해당됩니다. 이러한 작업은 대개 CPU를 많이 사용하지 않지만, 다른 HW Resource를 많이 사용하며, 상대적으로 더 많은 시간이 소요됩니다.
❗️ CPU Bound, I/O Bound 작업과 Process, Thread의 관계를 살펴봅시다.
• Process와 Thread는 각각이 독립적으로 실행될 수 있는 프로그램 실행 단위입니다. Process는 프로세스 간 독립성을 보장하고, Thread는 프로세스 내에서 각각의 스레드 간 공유성을 보장합니다.
• CPU Bound 작업은 대개 계산 집약적인 작업으로, 단일 Process 내에서 수행할 때 CPU 리소스를 최대한 활용할 수 있습니다. 이 때문에, CPU Bound 작업은 프로세스를 사용하여 병렬 처리하고, Multi Processing을 통해 처리 성능을 향상하는 것이 유리합니다.
• I/O Bound 작업은 파일 시스템, Network, DB 등의 외부 리소스에 의존하므로, CPU 리소스를 대부분 사용하지 않습니다. 따라서 I/O Bound 작업은 스레드를 사용하여 병렬 처리하고, Multi Threading을 통해 처리 성능을 향상하는 것이 유리합니다.
➕ 동기화와 병렬 처리에 관한 정보가 필요하시다면 여기에서 정보를 얻으실 수 있습니다.
➕ Process와 Thread에 관한 추가 정보가 필요하시다면 여기에서 정보를 얻으실 수 있습니다.
➕ Python 성능과 GIL에 관한 정보가 필요하시다면 여기에서 정보를 얻으실 수 있습니다.
🍎 병목이 발생하는 부분을 알아보고 해결해 봅시다.
☑️ Crawling 할 세 개의 사이트들은 동기로 처리해야 할 필요가 있을까?
🍏 Crawling target site들을 실행하는 부분에서 순서대로 Crawling이 진행돼야 하는지 생각해 봤습니다.
• Selenium을 걷어내고 난 후 Crawling Application 실행 부분의 모습입니다. 아래 코드를 실행시킨다면 세 사이트를 차례대로(동기적으로) 처리됩니다. 그런데 동기로 처리해야 할 필요가 있을까요?
• 세 사이트의 공통점은 Crawling 할 대상의 사이트라는 것 외엔 존재하지 않습니다. 세 사이트의 URL 주소도 다르고 HTML Source안에 내용 역시 다릅니다. 이는 세 작업을 동시에 처리해도 서로의 영역에 영향을 끼치지 않은 것을 의미합니다. (변경 이전 코드는 여기서 확인하실 수 있습니다.)
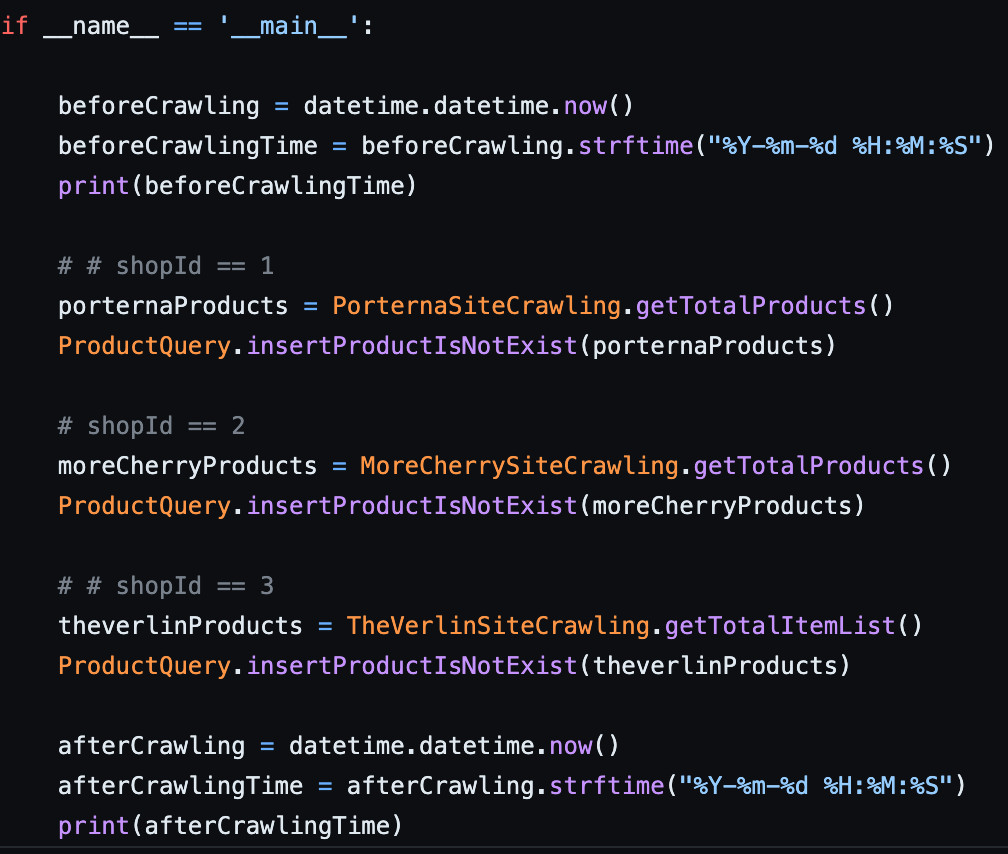
변경 이전 실행 부분 ✅ 변경 결과
• Python Multiprocessing Module을 통해 각각의 사이트들을 병렬로 처리했습니다. MultiProcess Pool에 Crawling 대상 사이트들을 넣고 Process를 띄워 각각 실행하게 합니다.
• pool이 갖고 있는 함수 map() 혹은 imap()을 사용하면 Pool의 close(), join()을 하지 않아도 됩니다.
• close()는 더 이상 Pool 객체에 새로운 작업을 추가하지 않는 걸을 명시적으로 선언하고, join()은 모든 작업이 완료될 때까지 대기하는 메서드입니다.

Process 세 개로 Crawling 사이트를 처리합니다. ☑️ CPU가 잘하는 일과 I/O가 잘하는 일을 나눠보자
• 아래는 한 사이트의 Crawling Logic 일부입니다. 병목 부분이 보이시나요? 아래 코드가 하는 역할을 간략하게 설명하자면 "각 페이지의 URL을 요청하고 받아온 응답을 BeautifulSoup에 넣어 Crawling"을 하는 것입니다.
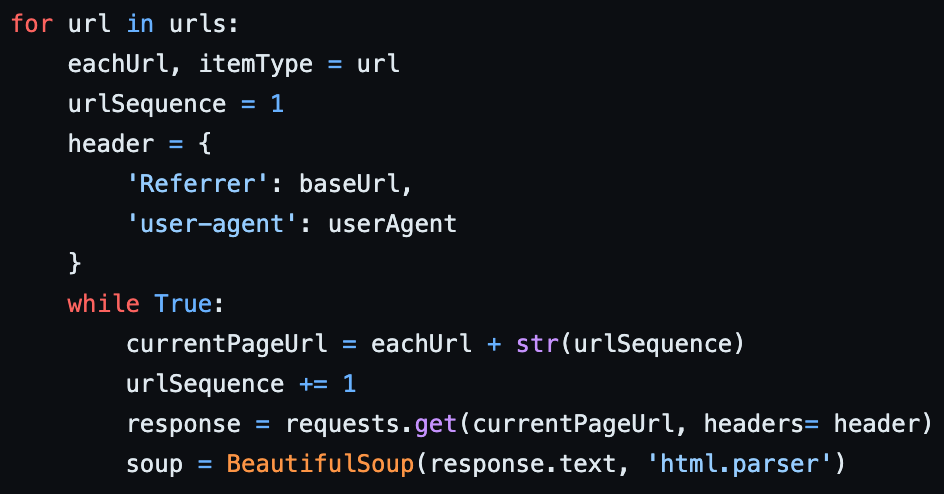
변경 이전 Crawling 작업 처리 부분 ✅ 페이지 URL 요청(I/O Bound 작업)에 응답을 기다리고 BeautifulSoup(CPU Bound 작업)을 사용합니다.
• Request.get()을 통해 response를 받아오고난 후 BeautifulSoup을 사용할 수 있게 됩니다. 이는 CPU Bound 작업을 수행하려면 I/O Bound 작업이 끝나고 진행해야 한다는 것입니다. 즉, 동기로 처리됨을 의미합니다. 이를 해결하기 위해 I/O Bound 작업과 CPU Bound 작업을 분리해야 합니다.
• 분리 후 I/O 작업이 많을 때 사용하면 유리한 Thread를 사용해 처리하고 CPU 작업이 많을 때 사용하면 유리한 Process를 사용해 처리합니다. 결과는 JBLY 프로젝트에서 확인하실 수 있습니다.
❓ BeautifulSoup을 사용하는 것이 왜 CPU가 사용되는 작업인가요?
• BeautifulSoup은 HTML 문서를 파싱하고 파싱 된 결과를 트리 형태로 표현하는데(HTML DOM) 많은 CPU 자원을 사용합니다.
• HTML 문서는 종종 복잡하고 중첩된 구조를 가지고 있기 때문에, 파싱 작업이 많은 연산을 필요로 하며, 이에 따라 CPU 자원을 많이 사용하게 됩니다.
• 추가로, BeautifulSoup은 파싱 된 HTML 트리를 탐색하고 수정하는 기능도 제공합니다. 이러한 작업은 더 많은 CPU 자원을 필요하며 더 복잡한 작업을 수행할수록 CPU 사용량도 증가합니다.
❗️상세 페이지 Crawling 부분도 병렬로 처리하면 더 빠르지 않을까?
• 상세 페이지를 Crawling 하는 부분도 위와 마찬가지로 I/O Bound 작업과 CPU Bound 작업이 묶여있었습니다. 이 부분을 반복문에서 분리해 내 성능을 높일 수 있었습니다.
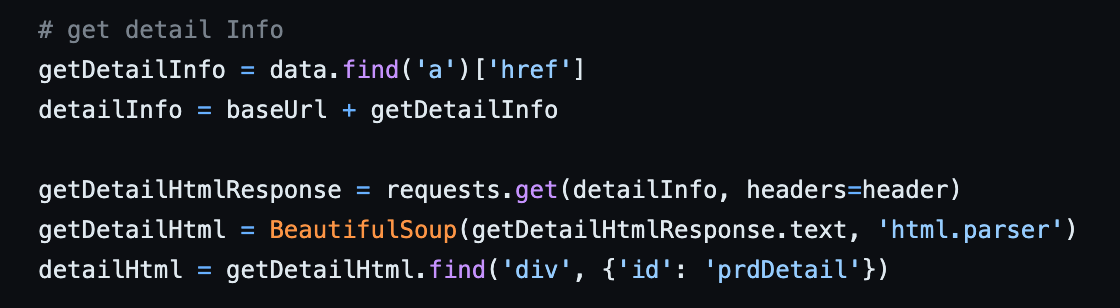
변경 이전 상세 페이지 🍎 Crawling Application Multi Process, Multi Thread 구성
🍏 상품의 정보를 가져오는 부분의 Process, Thread 구성도입니다.
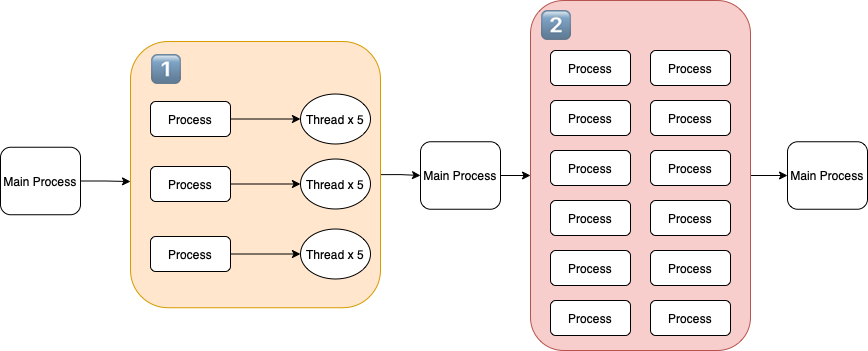
상품 정보를 Crawling할 때 사용되는 Process와 Thread 구조 1. 처음 단계는 Crawling 대상 페이지를 모으는 과정입니다. 카테고리 별로 1페이지부터 마지막 페이지까지 가져오는 작업을 수행합니다.
• JBLY 프로젝트에서 요구된 상품 카테고리는 총 5가지이며 각 Thread 당 각 카테고리 첫 페이지를 넣고 요청에 대한 응답을 받아옵니다.
2. 두 번째 단계에선 받아온 Response를 BeautifulSoup에 넣어 HTML을 그리고 HTML Parsing 과정이 일어납니다.
• 해당 과정은 CPU Bound 작업이며 Process의 개수는 Hyper Threading을 지원하기 때문에 작업하는 PC Core 개수 * 2로 설정했습니다. (작업하는 Computer의 Core의 개수는 6입니다.)
🍏 상세 상품의 정보를 가져오는 부분의 Process, Thread 구성도입니다.

상품 상세 정보를 Crawling할 때 사용되는 Process와 Thread 구조 3. 세 번째 단계에선 Crawling 한 4305개의 상품에 대한 상세 페이지 I/O 작업을 처리합니다.
• Single Process * Multi Thread(36개) 보다 Multi Process(3개) * Multi Thread(12개)의 성능이 더 빠르기 때문에 위와 같이 구성했습니다.
4. 네 번째 단계에선 4305개의 response를 BeautifulSoup에 전달해 CPU Bound 작업을 수행합니다.
• 2 번째 단계와 마찬가지로 현재 작업을 진행 중인 Computer Core 개수 * 2의 Process를 사용해 상세 페이지 Crawling을 수행합니다.
➕Crawling Application 실행하는 Computer의 자원, Network 환경에 Process, Thread는 영향을 받습니다. 환경에 맞게 설정을 해주고 자원을 쥐어짠다면 더 빠른 시간 내에 Application 실행을 마칠 수 있을 것입니다.
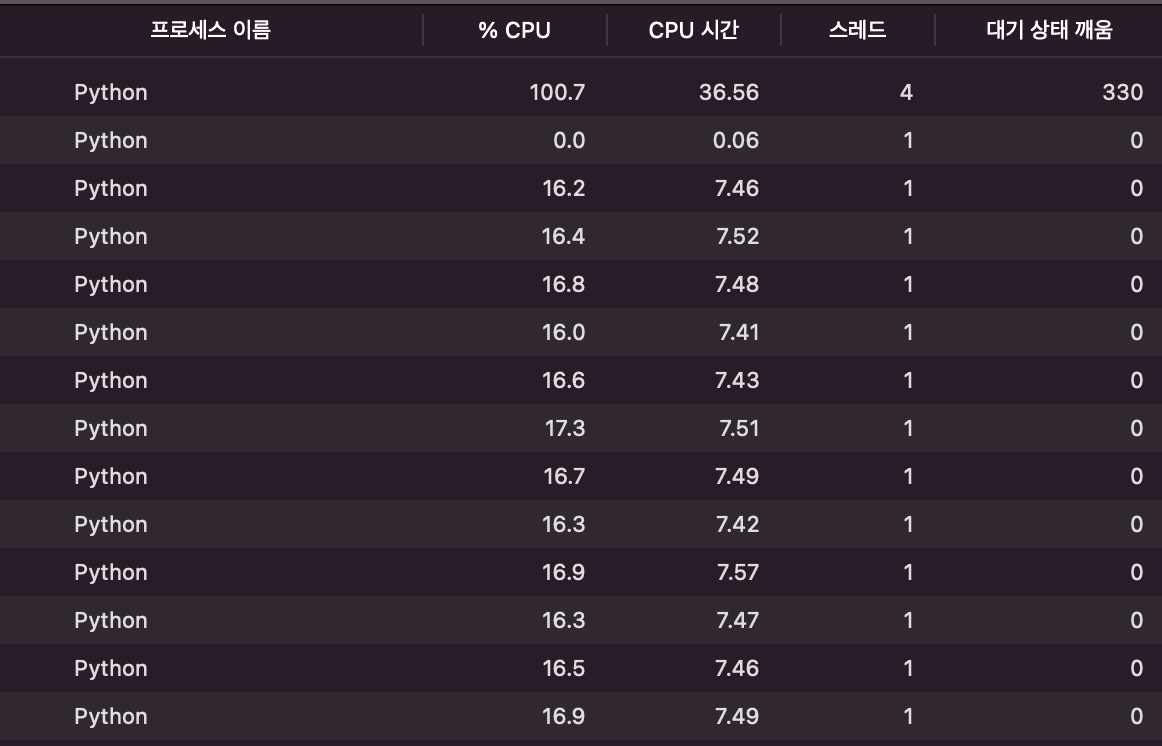
💻 사용하는 컴퓨터의 자원을 활용하는 것은 (Mac OS 기준) "활성 상태 보기"를 통해 측정할 수 있습니다.
• CPU 자원을 사용한 모습입니다. Main CPU 사용 퍼센티지를 보면 자원을 최대한 사용하고 있다는 것을 알 수 있습니다.
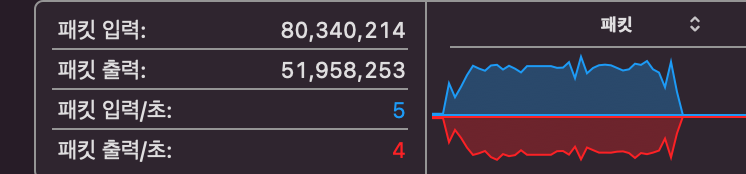
• 패킷 단위로 데이터를 송/수신하는 Network 모습입니다.
✅ Multi Process와 Multi Thread를 사용한 병렬처리로 160분 걸리던 Crawling Application 실행 시간이 4분대로 줄었습니다.
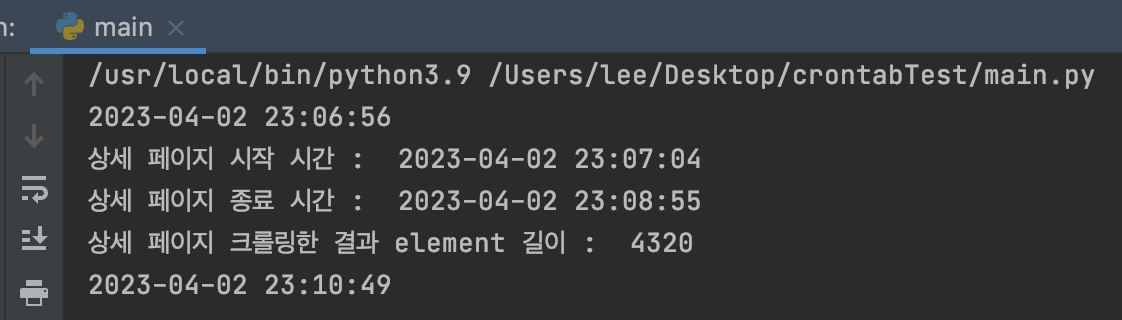
성능 개선 결과 • I/O Bound 작업과 CPU Bound 작업을 떼어내고 작업을 병렬로 처리해 Crawling을 마칠 수 있었습니다.
• 1000개의 사이트를 모아보는 서비스를 제공할 때 대략적으로 계산해 보겠습니다.
• 하루에 처리할 수 있는 Crawling Site 개수 : 4분에 3개 사이트를 처리할 수 있으니, 45개 Site를 한 시간에 처리할 수 있습니다. 45개 Site * 24 시간 = 1080 개의 사이트를 처리할 수 있습니다.
• 성능 개선이 이뤄지지 않았을 땐 한 달이 넘어도 모든 사이트를 처리할 수 없었는데 지금은 23시간보다 적은 시간에 모든 사이트를 Crawling 해올 수 있었습니다.!
• 소비자에게 제공될 데이터와 쇼핑몰에서 제공하는 데이터 정합성 문제가 발생할 가능성이 있지만 최악의 경우 하루정도 차이가 발생하게 됩니다. 한 달 넘게 데이터 불일치 가능성에서 많은 개선이 이뤄졌습니다.
❓ 성능을 더 개선할 방법은 없는 건가요?
• 아닙니다. 아직 개선할 부분이 있습니다. 모든 사이트들은 쇼핑몰이라는 공통점만 존재하지 사이트 간 접점이 없습니다.
• HW 자원이 충분하게 주어진다면 1000개의 사이트를 100개씩 Chunk 한 후 10개의 독립적인 Process에서 처리하게 한다면 낙관적인 계산으로 138분(2시간 18분)에 모든 사이트를 처리할 수 있습니다.
📚 참고 사이트
파이썬 Multi Processing에 관한 정보를 얻을 수 있습니다.
🍎 전체 프로젝트는 JBLY 프로젝트에서 확인 가능합니다.
🍎 Github 주소 : 친환경 사과
EcoFriendlyAppleSu - Overview
EcoFriendlyAppleSu has 24 repositories available. Follow their code on GitHub.
github.com
'Dev Azit > 크롤링 성능튜닝 여행기' 카테고리의 다른 글
Crawling 성능 40배 올리기, 160분에서 4분대로 -도구 선택의 중요성- (3) 2023.04.05 Crawling 성능 40배 올리기, 160분에서 4분대로 -요구사항 충족- (2) 2023.04.04